- 12 Posts
- 9 Comments




 3·4 months ago
3·4 months agoI don’t think that’s a use case the developers really envisaged.
I know under movies (and possible shows as well), you can specify versions:
https://jellyfin.org/docs/general/server/media/moviesBut I think you’re expected to select the version at playback time.
When I’ve had this issue, I’ve just transcoded to a format that all my targets can read without drama and kept the resulting file.
If your keen to experiment, I’d be curious to hear the outcome.
As /u/[email protected] said, you can try to force a scan of the library. Log into the admin and hit the big “Scan All Libraries” button, then give it some time.
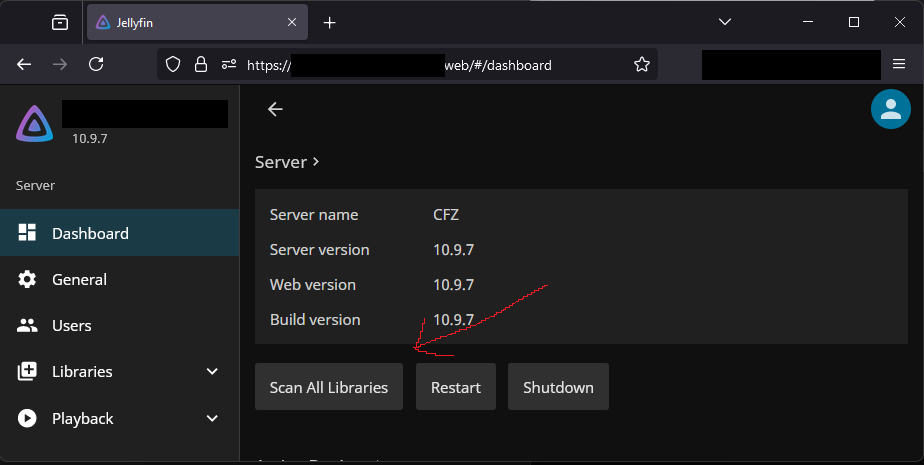
A refresh of that page should show a progress meter.
In order to encourage more accurate detection (assuming it can find/access the new file at all), there are advised naming schemes for your files. See here for a basic overview: https://jellyfin.org/docs/general/server/media/movies
I prefer to include the full name, year and imdb info of a movie, ie Citizen Kane isn’t just “Citizen.Kane.mp4”, it’s:
“Citizen Kane (1941) [imdbid-tt0033467].mp4”
based on the information that’s publically available here https://www.imdb.com/title/tt0033467/Even if you don’t enable imdb itself for the metadata lookup, that will give you an almost guaranteed detection during a library scan.
If this sounds like too much work, there’s several automated tools for naming your personal dvd rips, such as Radarr.
If it’s still not being detected, it’s time to dig into the logs and find out WHY it’s erroring.
Is it permissions?
Is it naming?
Is it the phase of the moon?




.1 was hotfixes to do with the major release.
Everything since then appears to just be shipping features as soon as they are proven stable.
I’ve updated 10.9.1 -> 10.9.2 -> 10.9.3 (and I’m about to do .4) and I just manually fire off the trickplay generating task after each update.
It quickly walks through the files that have already been done and then resumes processing from where it left off.
Currently at 13% after like 10 days or whatever it is.

Looks like it’s a manual process.
It also looks like no Jellyfin developer is creating the builds on Flathub and that some random member of the flathub community did it.Whilst the devs provide instructions for all manner of install methods, the preferred version is definitely via docker.

Yeah, I can see it now.
I can only assume that the post hadn’t propagated to my server 3 hours ago.

Short answer no.
Plex works by having a centralised server run by Plex themselves, that facilitates your client connecting to your server.The external facing part of Jellyfin server is basically a web server, and it’s a bad idea to expose that to the internet without putting a reverse proxy in front of it (hence the mention of NGINX above).
Another option is to have a VPN connection to where you are running Jellyfin and then only access Jellyfin pseudo locally (so potential security problems aren’t a big concern). This introduces other complications if you want to access it remotely via things like Roku or Chromecast, especially if you have multiple external (and probably not tech savvy) users.I want to stress that none of this is prohibitively expensive or hard, but doing it involves learning and effort.
All the information and programs you need are available online for free.If you only wanted to use Jellyfin at home (server in the cupboard, client on the tv), none of this other stuff matters. If you want to access Jellyfin remotely, and the idea of running a reverse proxy or a vpn server with the corresponding exposed ports and domain configuration sounds scary, Jellyfin is probably not for you.
pihole blocks ads by refusing to return dns results of known ad hosting URLs.
Chromecast ignores your DHCP supplied dns UNLESS 8.8.8.8 and 8.8.4.4 are inaccesible.
People who’s bothered to do this have added static routes to make all requests on port 53 go to the pihole.
https://www.reddit.com/r/pihole/comments/uaov2a/how_can_i_override_chromecasts_hardcoded_google/
Have you told the library to rescan after making the change?