

Case sensitivity is how we get SovCits……
Uh wat
Look at a lot of postings in the “insanepeoplefacebook” community. There are a lot of “sovereign citizens” who believe that when you’re born the government makes a corporation using the all caps version of your name. And that the case sensitivity of how your name appears on bills matters as they’re distinctly different people.
Ah I gotcha now. I forgot about the capitalization stuff haha!
But why though? Do you really want a bunch of file.txt File.txt FILE.txt fIle.txt FiLe.txt FIle.txt flIe.txt… I once had a nasty bug the O in a file name was a 0 and I didn’t notice I can’t imagine the horrors this would cause.
Yeah I’ve definitely run into issues where case sensitivity causes problems. Especially in programs that are cross-functional between Windows and Linux. Like when I recently downloaded some bios files for a Playstation emulator and I spend time figuring out and troubleshooting why they weren’t working until it finally hit me the door McFly it’s cause the file name was in lowercase not uppercase. Than I cared to admit to figure out
Oooh, I’ve had that with some device. I think it was a camera or something like that. I’d forgotten about it. It took me ages to figure it out.
Windows and NTFS support case sensitive filenames. The functionality is disabled for compatibility reasons.
I remember the good old days of Windows MS-DOS where they had an 8 character filename limit lol
8.3, actually!
Gotta go count my files again… oh yeah it’s PROJE~14.BAS
haha that was so infuriating. if their intent was to bastardize the filename horribly to make it noticeable that you defied the DOS limitation, they certainly succeeded. Yuck, totally forgot about the
~1thing!
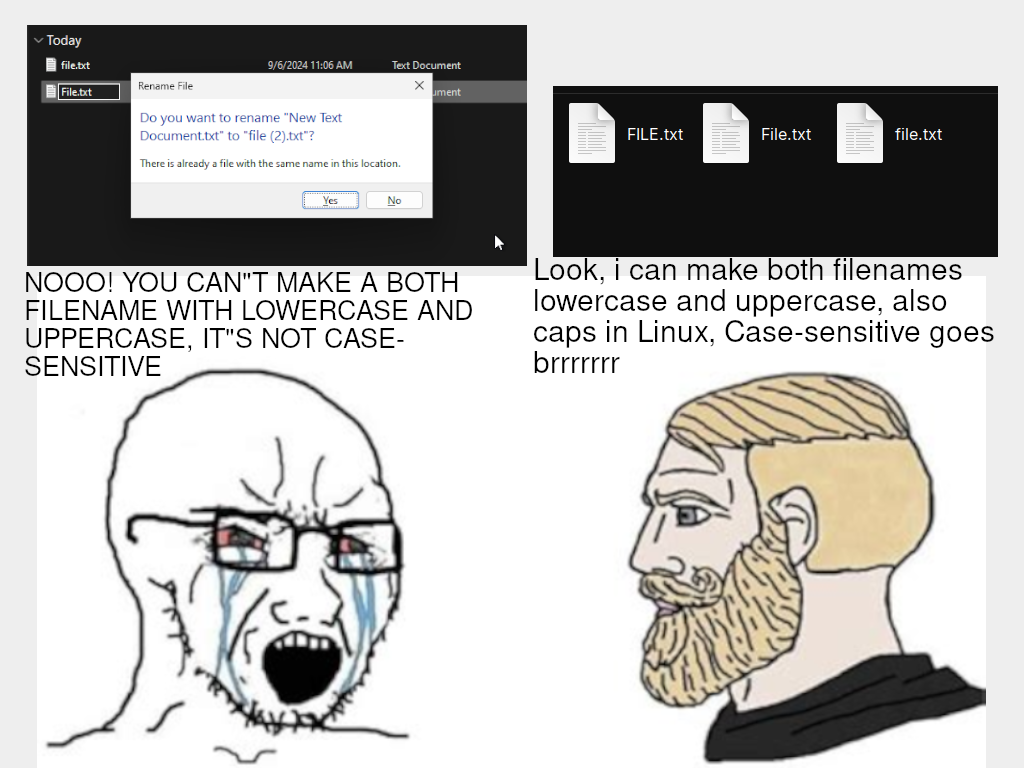
HEY, NOT ALL OF US CAN AFFORD LOWER-CASE LETTERS
file.txt
file.TXT
file.tXt
etcThe meme faces are backwards on this one.
What I really like is a naming files with a forbidden windows character in Linux and they wont copy over to a windows partition. I end up using a question mark quite a bit for some reason.
Or just name the file
con. Windows 95 even used to bluescreen if you tried to refer tocon\con.touch 'C:\WINDOWS\SYSTEM32'
Oh it’s even better, windows explorer can’t really do case sensitive
But NTFS is a case sensitive file system
This occasionally manifests in mind boggling problems
Yeah, it’s super weird. I once named a file with mixed case, but one of the letters was the wrong case. Renaming the file didn’t work at first. Renaming a file named PAscalCase.txt to PascalCase.txt resulted in no change to the filename. Windows continued to show it as PAscalCase.txt. I had to rename it to something totally different with different characters entirely, then rename it again to get it right.
I can make a file named COM1 on Linux. That’s on the forbidden list for Windows.
The forbidden list:
- CON
- PRN
- AUX
- CLOCK$
- NUL
- COM1
- COM2
- COM3
- COM4
- COM5
- COM6
- COM7
- COM8
- COM9
- LPT1
- LPT2
- LPT3
- LPT4
- LPT5
- LPT6
- LPT7
- LPT8
- LPT9
deleted by creator
So is Linux, but it puts stuff like that in /dev
The thing is, a lot of the legacy backwards compatible stuff that’s in Linux is because a lot of things in Unix were actually pretty well thought out from the get go, unlike many of the ugly hacks that went into MSDOS and later Windows and overstayed their welcome.
Things like: long case sensitive file names from the beginning instead of forced uppercase 8.3 , a hierarchical filesystem instead of drive letters, “everything is a file” concept, a notion of multiple users and permissions, pre-emptive multitasking, proper virtual memory management instead of a “640k is enough” + XMS + EMS, and so on.
Unix was designed for mainframes, qdos/msdos was designed to be a cpm knockoff the local nerd could use to play commander keen and do his taxes. It’s actually impressive how much modern/business functionality they were able to cram into that.
Unix was designed for mainframes
Unix was never for mainframes. It was for 16-bit minicomputers that sat below mainframes, but yes they were more advanced than the first personal computers.
It’s actually impressive how much modern/business functionality they were able to cram into that.
Absolutely, but you have to admit that it’s a less solid foundation to build a modern operating system on.
In the 80s, there were several Unices for PC too btw: AT&T, SCO, even Microsoft’s own Xenix. Most of them were prohibitively expensive though.
Thought experiment: Would you expect a programming language variable name to be case insensitive?
That is, if you set
foo = 1and thenprint FOO, what should happen? Most programming languages throw an error.Is this even comparable with filenames, which are, after all, basically variable names that hold large quantities of data?
If there is a difference, is it the fact it’s a file, or - for a mad idea - should files with only a few bytes of data retain case insensitivity? And if that idea is followed through, where’s the cutoff? 256 bytes? 7?
(Anyway, Windows filenames are case sensitive, in a sense. If you save “Letter to Grandma.txt” it will retain those two capital letters and all the lower case letters exactly as they are. It won’t suddenly change to “LETTER to Grandma.txt”, despite the fact that if you try to open a file by that name, you’ll get the same file.)
PowerShell variable names and function names are not case sensitive.
I understand the conventions of using capitalization of those names having specific meanings in regards to things like constants, but the overwhelming majority of us all use IDEs now with autocomplete.
Personally, I prefer to use prefixes anyway to denote that info. Works better with segmenting stuff for autocomplete, and has less overhead of deriving non-explicit meaning from stuff like formatting or capitalization choices.
On top of that, you really shouldn’t be using variables with the same name but different capitalization in the same sections of code anyway. “Did I mean to use $AGE, $Age, or $age here?” God forbid someone come through to enforce standards or something and fuck that all up.
But should $Age return the same value as $age if used in its place by mistake?
you really shouldn’t be using variables with the same name but different capitalization in the same sections of code anyway.
It’s a standard convention. Notice step #3 here: https://scottlilly.com/learn-c-by-building-a-simple-rpg-index/lesson-08-1-setting-properties-with-a-class-constructor/
Edit: Step #4 is a different standard convention that also applies here.
This is one case where I think Windows is appropriately designed for its target audience.
This isn’t “Windows design”… this is just inherited stone age bullshit from the DOS days when the filesystem was FAT16 and all file names were uppercase 8.3.
NTFS is case sensitive in its underlying design, but was made case insensitive by default, yet case preserving, for reasons of backwards compatibility.
If Microsoft has to design something from scratch, without the need for backwards compatibility, they go for case sensitive themselves. For example: Azure Blob Storage has case sensitive file names.
If you rename a file only changing the casing it doesn’t update properly, you need to rename it to something else and back.
This is so userfriendly I have been stumped by it multiple times.On the other hand in using Linux I have had a number of problems with the casing of files: The number is 0
If you rename a file only changing the casing it doesn’t update properly, you need to rename it to something else and back. This is so userfriendly I have been stumped by it multiple times.
To my great surprise, this has been fixed. I don’t know when, but I tried it on my Windows 10 VM and it just worked. Only took them 20 years or so :)
case insensitive by default, yet case preserving
This isn’t just a Windows thing… It’s the same on MacOS by default.
I don’t really see the benefit of allowing users to create files with the same name in the same directory, yeah, yeah I know that case sensitivity means that it isn’t same name, but imagine talking to a user, guiding them to open the file /tmp/doc/File and they open /tmp/doc/file instead
Let’s say you have a software that generates randomly named files, having the ability to use both upper case and lower case means you can have more files with the same amount of characters, but that sounds horrible and it’s the only thing I can think of atm
The reason, I suspect, is fundamentally because there’s no relationship between the uppercase and lowercase characters unless someone goes out of their way to create it. That requires that the filesystem contain knowledge of the alphabet, which might work if all you wanted was to handle ASCII in American English, but isn’t good for a system which needs to support the whole world.
In fact, the UNIX filesystem isn’t ASCII. It’s also not unicode. UNIX uses arbitrary byte strings, with special significance given to a very small number of bytes (just ‘/’ and ‘\0’, I think). That means people are free to label files in whatever way they like, and their terminals or other applications are free to render them in whatever way seems appropriate, without the filesystem having to understand unicode.
Adding case insensitivity would therefore actually be significant and unnecessary complexity to add to the filesystem drivers, and we’d probably take a big step backwards in support for other languages
You’re basically arguing that a system shouldn’t support user friendly things because that would add significant burden to the programmer.
The quintessential linux philosophy. Well done! I mean, what is language? Why have named code variables? This is just a random array of bytes!
No, I’m arguing that the extra complexity is something to avoid because it creates new attack surfaces, new opportunities for bugs, and is very unlikely to accurately deal with all of the edge cases.
Especially when you consider that the behaviour we have was established way before there even was a unicode standard which could have been applied, and when the alternative you want isn’t unambiguously better than what it does now.
“What is language” is a far more insightful question than you clearly intended, because our collective best answer to that question right now is the unicode standard, and even that’s not perfect. Making the very core of the filesystem have to deal with that is a can of worms which a competent engineer wouldn’t open without very good reason, and at best I’m seeing a weak and subjective reason here.
Windows way is superior, in my opinion. I don’t think there’s a need for File.txt and fILE.txt
I don’t think there’s a need for File.txt and fILE.txt
It’s not so much about that need. It’s about it being programmatically correct.
fandFare not the same ASCII or UTF-8 character, so why would a file system treat them the same?Having a direct
chartype to filename mapping, without unnecessary hocus pocus in between, is the simple and elegant solution.That’s some suckless level cope. What’s correct is the way that creates the least friction for the end users. Who really cares about some programming purity aspect?
That’s some suckless level cope
Thanks, really constructive way of arguing your point…
Who really cares about some programming purity aspect?
People who create operating systems and file systems, or programs that interface with those should, because behind every computing aspect is still a physical reality of how that data is structured and stored.
What’s correct is the way that creates the least friction for the end users
Treating different characters as different characters is objectively the most correct and predictable way. Case has meaning, both in natural language as well as in almost anything computer related, so users should be allowed to express case canonically in filenames as well. If you were never exposed to a case insensitive filesystem first, you would find case sensitive the most natural way. Give end users some credit, it’s really not rocket science to understand that
fandFare not the same, most people handle this “mindblowing” concept just fine.Also the reason Microsoft made NTFS case insensitive by default was not because of “user friction” but because of backwards compatibility with MSDOS FAT16 all upper case 8.3 file names. However, when they created a new file system for the cloud, Azure Blob Storage, guess what: they made it case sensitive.
surely Git warns about stuff like this when you clone it, right ?
It tells you there’s a name clash, and then it clones it anyway and you end up with the contents of
README.MDinREADME.mdas an unstaged change.sounds like actually a good solution … tho doesnt sound like it would work for more than 2 similarly-named files
I don’t think it’s intended as a “solution”, it just lets the clobbering that is caused by the case insensitiveness happen.
So git just goes:
- checkout content of README.md to README.md (OS creates README.md)
- checkout content of README.MD to README.MD (OS overwrites README.md)
If you add a third or fourth file … it would just continue, and file gets checked out first gets the filename and whichever file gets checked out last, gets the content.
And i hate it being case sensitive
Yeah, right? Are we pretending that having case sensitive file names isn’t a bad call, or…? There are literally no upsides to it. Is that the joke?
For files of casual users it might be of benefit. They don’t care about capitalization. For system files, I find it pretty weird to name them with random capitalization, and it’s actually pretty annoying. Only lower- (or upper-)case would be ok tho.
Well, camel case does help readability on file names. But I guess that’s the point of case insensitive names, it doesn’t matter. However you want to call them will work.
I’m with you here, i find it infuriating and i never ever had the situation where this was beneficial.
Like who tf actually creates a File.txt, file.txt AND FILE.TXT in one place and actually differentiates them with that.
For example I might store blobs of data processed by my database in files that have the Base64 ID of the blob as the filename. If the filesystem was case insensitive, I’d be getting collisions.
Users probably don’t make such files, no. But 99% of files on a computer weren’t created by the user, but are part of some software, where it may matter.
And often software originally written for Linux or macOS and then ported to Windows ends up having problems due to this.













{kind=link}