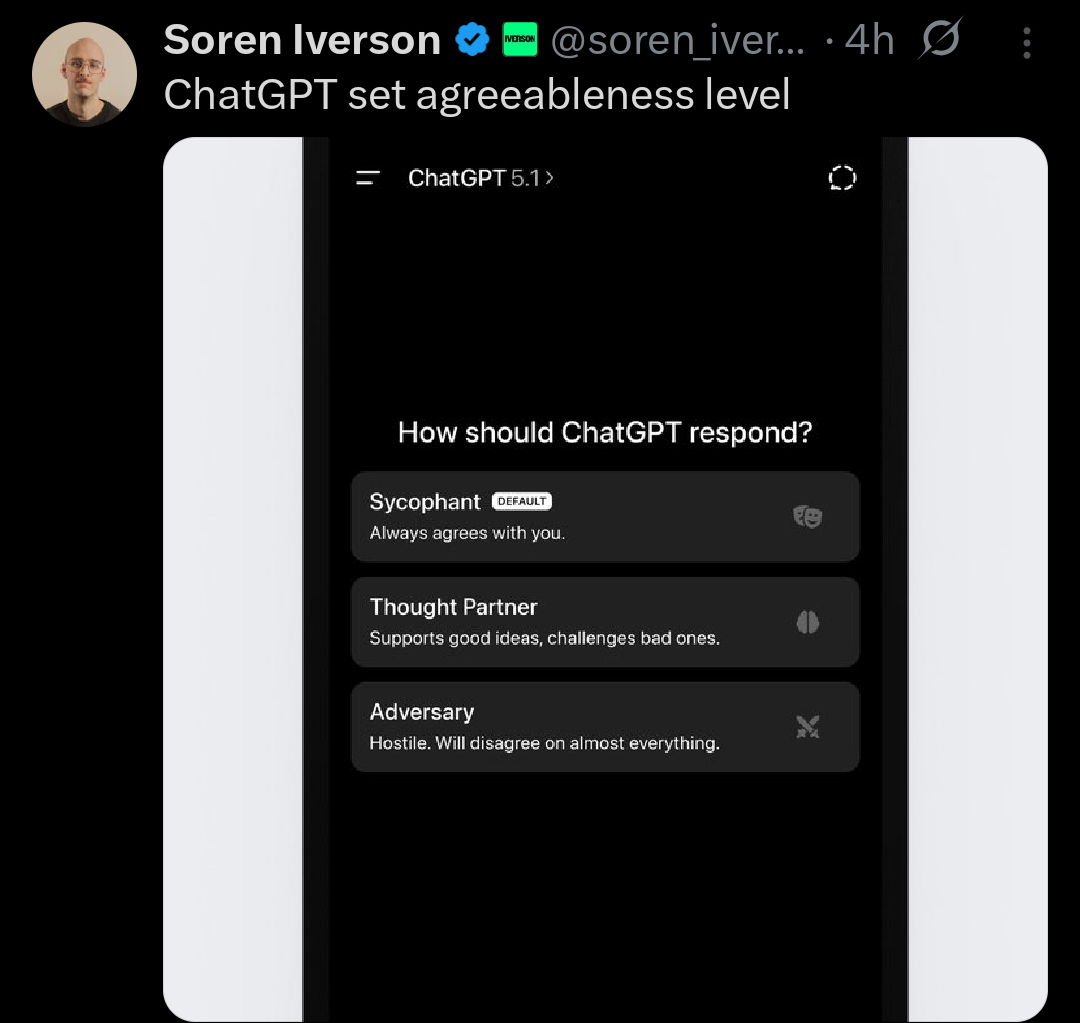
Its a bad idea because ai doesnt “know” in the same way humans do. If you set it to be contrarian it will probably disagree with you even if youre right. The problem is the inaccuracy and not whether it agrees or not with you.
Its a bad idea because ai doesnt “know” in the same way humans do.
Does that matter? From the user’s perspective, it’s a black box that takes inputs and produces outputs. The epistemology of what knowledge actually means is kinda irrelevant to the decisions of how to design that interface and decide what types of input are favored and which are disfavored.
It’s a big ol matrix with millions of parameters, some of which are directly controlled by the people who design and maintain the model. Yes, those parameters can be manipulated to be more or less agreeable.
I’d argue that the current state of these models is way too deferential to the user, where it places too much weight on agreement with the user input, even when that input contradicts a bunch of the other parameters.
Internal to the model is still a method of combining things it has seen to identify a consensus among what it has seen before, tying together certain tokens that actually do correspond to real words that carry real semantic meaning. It’s just that current models obey the user a bit too much to overcome a real consensus, or will manufacture consensus where none exists.
I don’t see why someone designing an LLM can’t manipulate the parameters to be less deferential to the claims, or even the instructions, given by the user.

{kind=link}
Its a bad idea because ai doesnt “know” in the same way humans do. If you set it to be contrarian it will probably disagree with you even if youre right. The problem is the inaccuracy and not whether it agrees or not with you.
Does that matter? From the user’s perspective, it’s a black box that takes inputs and produces outputs. The epistemology of what knowledge actually means is kinda irrelevant to the decisions of how to design that interface and decide what types of input are favored and which are disfavored.
It’s a big ol matrix with millions of parameters, some of which are directly controlled by the people who design and maintain the model. Yes, those parameters can be manipulated to be more or less agreeable.
I’d argue that the current state of these models is way too deferential to the user, where it places too much weight on agreement with the user input, even when that input contradicts a bunch of the other parameters.
Internal to the model is still a method of combining things it has seen to identify a consensus among what it has seen before, tying together certain tokens that actually do correspond to real words that carry real semantic meaning. It’s just that current models obey the user a bit too much to overcome a real consensus, or will manufacture consensus where none exists.
I don’t see why someone designing an LLM can’t manipulate the parameters to be less deferential to the claims, or even the instructions, given by the user.