
Arthur Besse
cultural reviewer and dabbler in stylistic premonitions
- 15 Posts
- 33 Comments


 2·26 days ago
2·26 days agoHi, I’m an admin on lemmy.ml. The account of the one existing mod of the session community here has apparently been deleted.
I’ve heard there are some bugs with moderation of remote communities, but, I just made you a mod there anyway. I don’t know the state of those bugs; it might work better if you made an account on this instance.
Btw, I recommend against using Session for a variety of reasons including the one I posted in your thread here.
 25·1 month ago
25·1 month ago/r/shittyaskredditwasn’t supposed to be an instruction manual 🙄
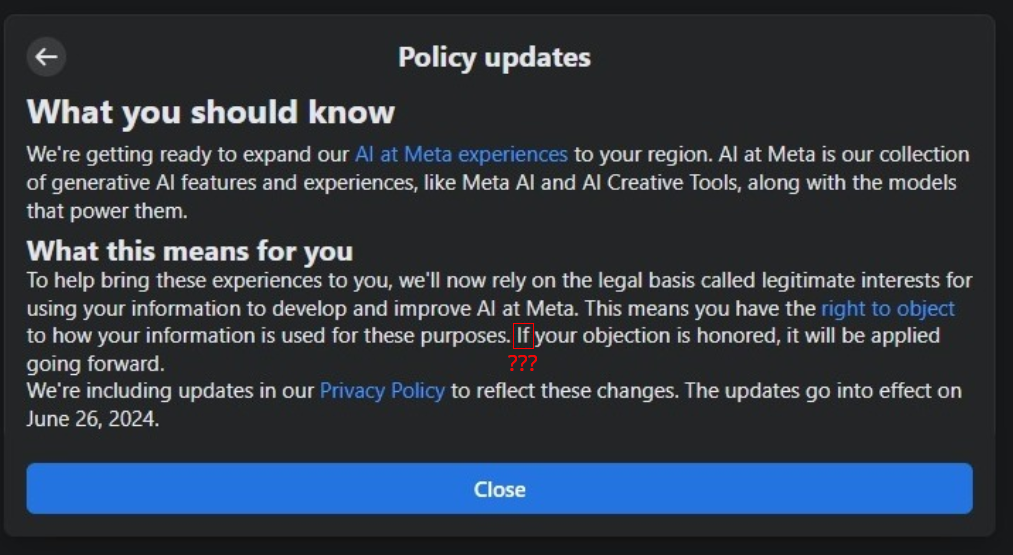
If your objection is honored, it will be applied going forward


 141·3 months ago
141·3 months agothat was predictable


via this thread here is a 🧲 magnet link for a torrent someone made containing “all their Github issues, the git repo on its last version, the latest available release binaries from the Github page, and all of their progress reports from the Yuzu website”.
someone did that before microsoft had even released WSA but I don’t see anything about people doing it recently. probably someone is working on it right now though, given this news.

i wonder how waydroid is these days. i still haven’t gotten around to trying it but I just looked again and I see its downloads are still hosted on Sourceforge 😖
apparently there was a proof-of-concept of it working on windows before Microsoft’s thing that died today had even been released. if many people actually used Microsoft’s thing I imagine some will turn their attention to waydroid now.
https://web.archive.org/web/20240303071843/https://github.com/yuzu-emu/yuzu/commits/master/
-> latest commit hash as of march 3rd was
15e6e48bef0216480661444a8d8b348c1cca47bb-> https://duckduckgo.com/?q=15e6e48bef0216480661444a8d8b348c1cca47bb (many copies of the repo exist)

LLM detractors hate this one weird trick
The ECHR ruling is good news (and there was already a post about it in this community and many others, a week ago, from a reputable publication), but this post about that news is actually spam for a company selling a snakeoil privacy product thinly disguised as news.
It’s worth taking note of the details of the court’s ruling in the context of Tuta’s architecture: this ruling specifically is not about when police demand that services like tuta use their capability to bypass encryption for specific users, which the architecture of services like Tuta very conveniently makes easy for them to do. Instead, it is about when authorities try to mandate that better-designed systems move to a tuta-like architecture to make targeted surveillance easy. Which makes Tuta’s use of this particular news for advertising purposes even more disgusting.
You have now banned me from both of those communities
I actually banned you from both of them at the same time I deleted those two protonmail posts, but then unbanned you a minute later after reviewing your account further.
You can view your modlog here.
You have deleted another post of mine
I commented about that deletion here.
fwiw i deleted the crossposts of this post from /c/[email protected] and /c/[email protected] (because protonmail is a faux-opensource snakeoil privacy product) and flagged the posts in other communities as spam.
i encourage anyone who thinks protonmail’s non-interoperable end-to-end encryption is useful to read my comment about it here.
edit: wow, such downvotes. i elaborated here.
it turns out the option was right there in their CMS all along!
🤦
it’s a shame that @NYTOnIt isn’t being updated anymore




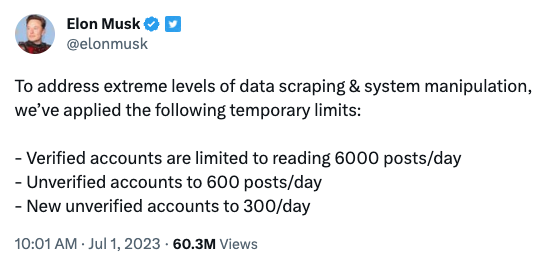



wikipedia articles about him have been deleted twice: