
nobody here asked for technical details, so I didn’t respond with technical stuff. but now that you ask, I can respond:
-
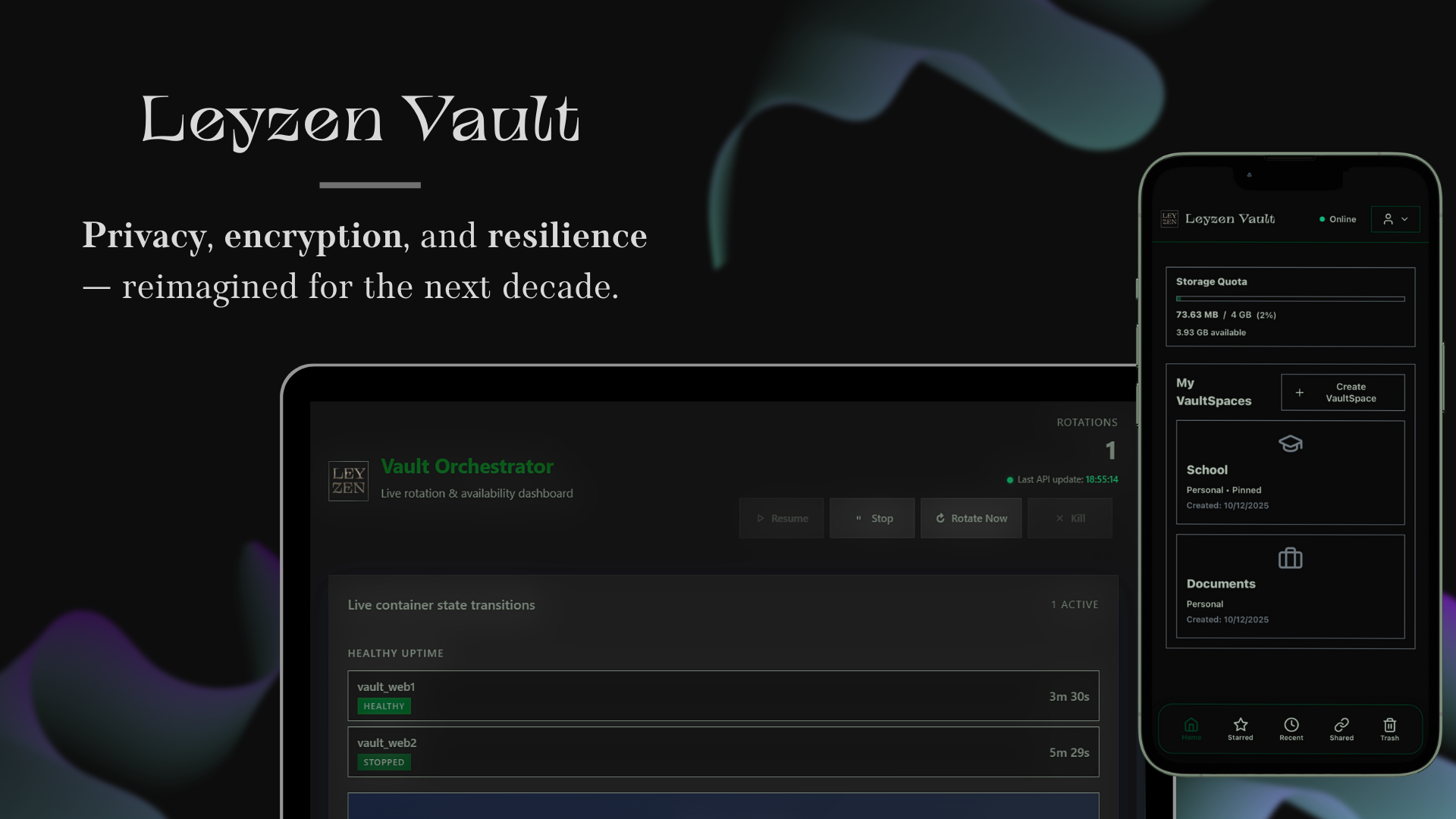
the rebuild occurs periodically. you set the period (in seconds) in the .env. a container named orchestrator stops and rebuilds vault containers by deleting every file that is not in the database and therefore not encrypted (like payloads). for event-based triggers, I haven’t implemented specific ones yet, but I plan to.
-
session tokens are stored encrypted in the database, so when a vault container is rebuilt, sessions remain intact thanks to postgres.
-
same as 2: auth tokens are stored in the database and are never lost, even when the whole stack is rebuilt.
-
yes, but not everything. since one container (the orchestrator) needs access to the host’s docker socket, I don’t mount the socket directly. instead, I use a separate container with an allowlist to prevent the orchestrator from shutting down services like postgres. this container is authenticated with a token. I do rotate this token, and it is derived from a secret_key stored in the .env, regenerated each time using argon2id with random parameters. and i also use docker network to isolate containers that doesn’t need to communicate between each other, like vault containers and the “docker socket guardian” container.
-
every item has its own blob: one blob per file. for folders, I use a hierarchical tree in the database. each file has a parent id pointing to its folder, and files at the root have no parent id.
-
can the app tune storage requirements depending on S3 configuration? not yet, S3 integration is a new feature, but I’ve added your idea to my personal roadmap. thanks.
and I understand perfectly why you’re asking this. No hate at all, I like feedback like this because it helps me improve.
Also, now that I’ve re-read this (I didnt understand what downvotes mean at first): why does a new project that doesn’t compete with big companies deserve downvotes? I’m just trying to meet tech people and talk about it, that’s all. It doesn’t need money, it doesn’t hurt anyone, and I’m not posting bullshit.
If it doesn’t solve a problem for you yet, that’s fine, it will get better over time. I genuinely want to understand what made you comment like this. And since you’re a moderator, respect btw, but why push people toward hating on it? What’s the goal here, should I delete the repo?