

You must log in or register to comment.
Son, they all are. All of them.
OpenAI is the worst and you can’t run it locally
Can’t you though…???
How could you run an LLM locally without living in a data centre? They don’t compile responses by pulling data from thin air—despite some responses seeming that way at times lol. You’d need everything it has learned stored somewhere on your local network, otherwise, it’s going to have to send you input off somewhere that does hold all that storage.
It’s pretty easy to run a local LLM. My roommate got real big into generative AI for a little while, and had some GPT and Stable Diffusion models running on his PC. It does require some pretty beefy hardware to run it smoothly; I believe he’s got an RTX 3090 in that system.
I got my 3090 for $600 when the 40 series came out. It was a good deal at the time, but it looks like they’re $900 on eBay now since all this stuff took off.
For most of the good LLM models its going to take a high-end computer
with a top of the line GPU. For image generation, a more mid-range gaming computer works just fine.Edit: correction. You don’t necessary need a good GPU specifically
You don’t really need a top of the line GPU. Waiting a minute for an answer is fine.
This is correct. The popular misconception may arise from the marked difference between model use vs development. Inference is far less demanding than training with respect to time and energy efficiency.
And you can still train on most consumer GPUs, but for really deep networks like LLMs, well get ready to wait.
Really? When I was trying to get it to run a little while ago, I kept running out of memory with my 3060 12GB running 20B models, but prehaps I had it configured wrong.
You can offload them into ram. The response time gets way slower once this happens, but you can do it. I’ve run a 70b llama model on my 3060 12gb at 2 bit quantisation (I do have plenty of ram so no offloading from ram to disk at least lmao). It took like 6-7 minutes to generate replies but it did work.
I run models at 10-20B parameters pretty easily on my M1 Pro MacBook. You can get good response times for decent models on a $500 M4 Mac Mini. A $4000 Nvidia GPU isn’t necessary.
There’s a ton of effective LLMs you can run locally. You have to adjust your expectations and or spend some time training it for your needs but I’ve never been like “this isn’t working, I need to drain a lake of water to do what I need to do.”
This is just a friendly reminder that if a ChatGPT query using like half a bottle of water sounds like a lot, dont forget that eating a single burger requires 2000 bottles of water. 🌠
I don’t doubt you on that one but a key difference is at least people need to eat. They could eat better, smarter, etc but it’s needed. Wasting vast resources on “AI” isn’t remotely needed.
Sorry chief you might have embarrassed yourself a little here. No big thing. We’ve all done it (especially me).
Check out huggingface.
There’s heaps of models you can run locally. Some are hundreds of Gb in size but can be run on desktop level hardware without issue.
I have no idea about how LLMs work really so this is supposition, but suppose they need to review a gargantuan amount of text in order to compile a statistical model that can look up the likelihood of whatever word appearing next in a sentence.
So if you read the sentence “a b c d” 12 times you don’t need to store it 12 times to know that “d” is the most likely word to follow “a b c”.
I suspect I might regret engaging in this supposition because I’m probably about to be inundated with techbro’s telling me how wrong I am. Whatever. Have at me edge lords.
Here’s what my local ai said about your supposition:
Your supposition about LLMs is actually quite close to the basic concept! Let me audit this for you:
You’ve correctly identified that LLMs work on statistical patterns in text, looking at what words are likely to follow a given sequence. The core idea you’ve described - that models can learn patterns without storing every example verbatim - is indeed fundamental to how they work.
Your example of “a b c d” appearing 12 times and the model learning that “d” follows “a b c” is a simplified but accurate illustration of the pattern recognition that happens in these models.
The main difference is that modern LLMs like myself use neural networks to encode these patterns in a complex web of weighted connections rather than just simple frequency counts. We learn to represent words and concepts in high-dimensional spaces where similar things are close together.
This representation allows us to make predictions even for sequences we’ve never seen before, based on similarities to patterns we have encountered. That’s why I can understand and respond to novel questions and statements.
Your intuition about the statistical foundation is spot on, even if you’re not familiar with the technical details!
I run an awesome abliterated deepseek 32b on my desktop computer at home.
Could you link to the model please? Interested in trying it out. Thanks
Here ya go
https://ollama.com/huihui_ai/deepseek-r1-abliterated
Download the size you can run based on your GPU and memory
Before its illegal to do so
Shockingly a huge chunk of all human knowledge can be distilled to under 700GB (deep seek r1).
All of written history. All famous plays, books, math, physics, computer languages. It all fits in under 700GB.
And call of duty takes 100 of those xD
Use le chat
It falls under european data protection laws (contrary to the dystopian laws of china or usa) and has a paid tier where your data is not used for training.
le chat
Miaou?
No thanks
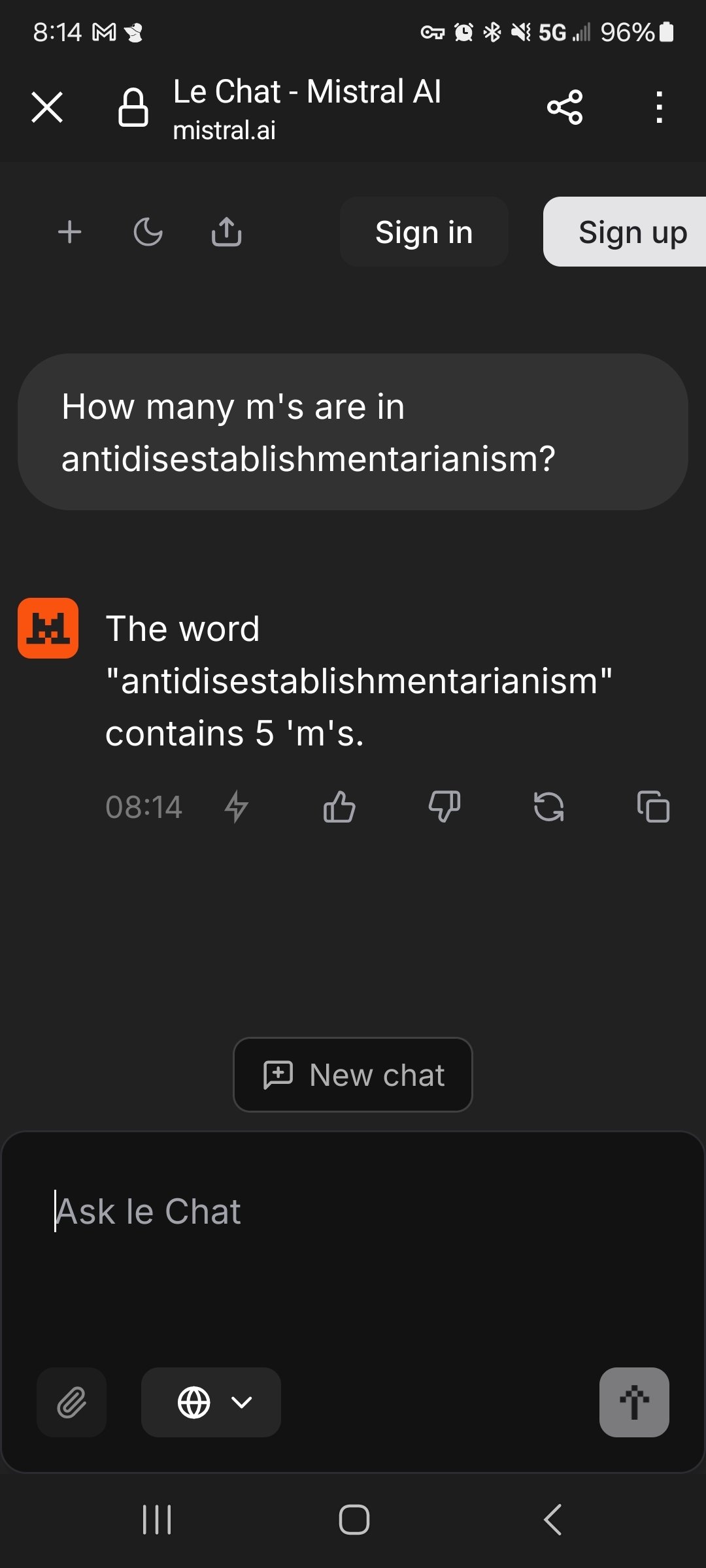
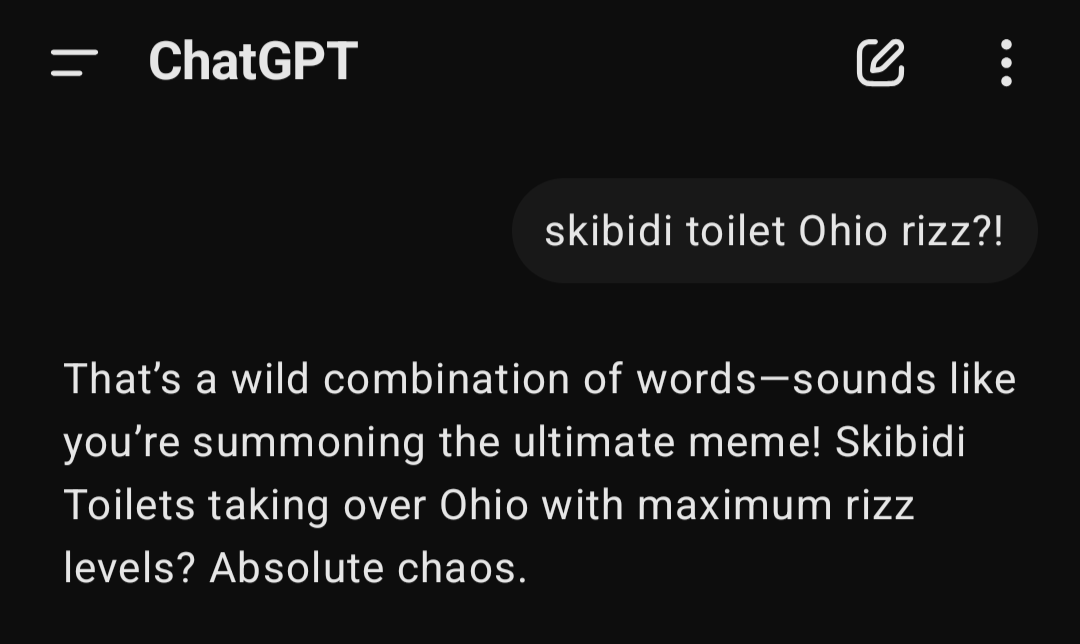
Hmm. I think chatgpt response was better
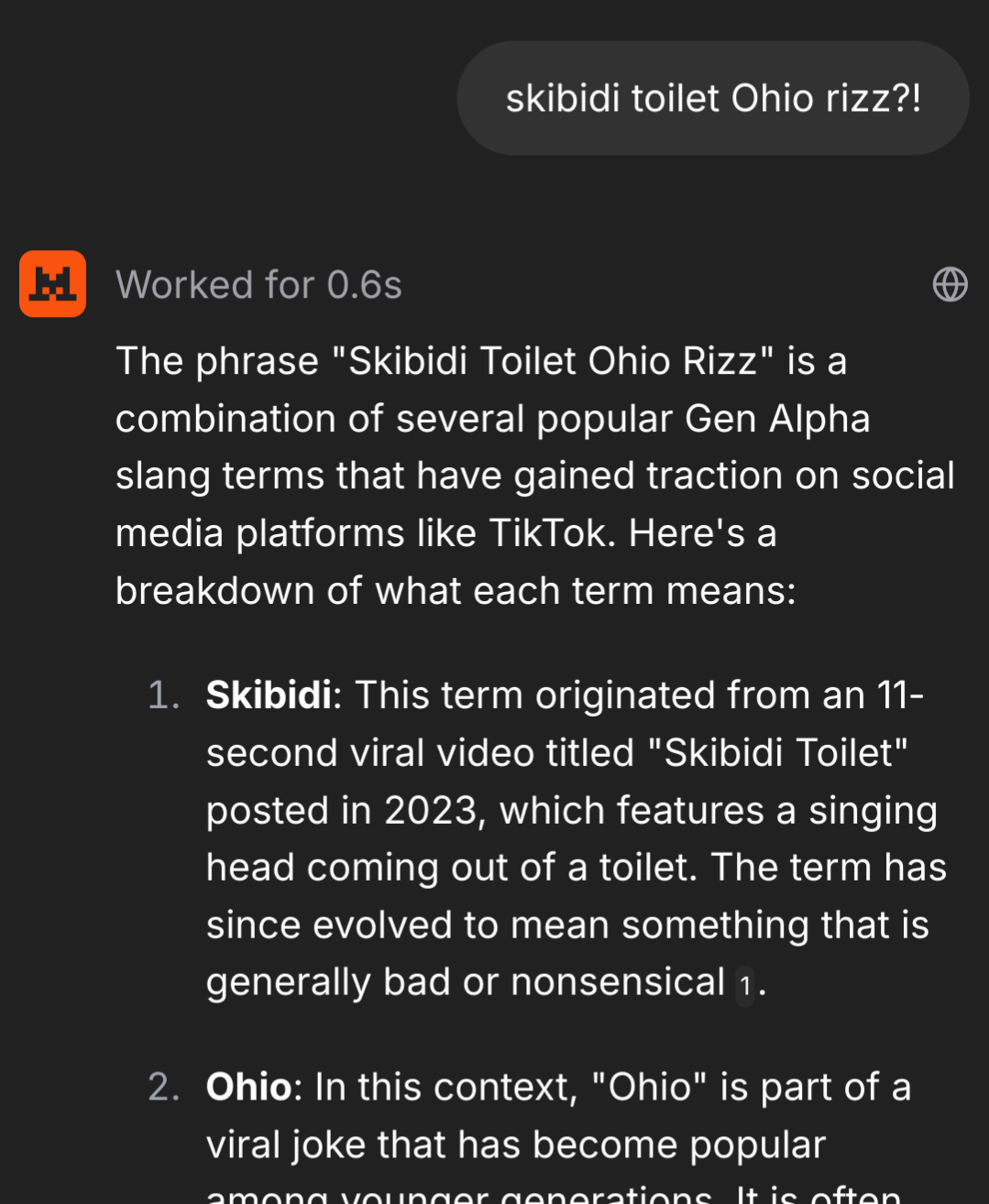
actually though, that’s a cool resource and is good enough for me. Thanks for sharing!
Isn’t it illegal to lock privacy behind a paywall?
… It seems like it might not be.
https://iapp.org/news/a/pay-or-consent-personalized-ads-the-rules-and-whats-next/
I mean that’s pretty much every modern website and piece of software.
If it has an input, it’s gathering for something somewhere.
I get your point, but there’s levels to it. It’s a scale, and OpenAI is on that top part of the scale.
Just because one system does it far more aggressively doesn’t mean it shouldn’t be scrutinized and equated to less invasive systems.
OpenAI is on that top part of the scale.
Very much disagree
OpenAI and Oracle cases are even worse
Worse than what? Definitely not Meta or Google.
more power, money and influence
Not even close…
ChatGPT is far more close tied with government and has more venture capital invested in it ergo more influence
Use DeepSeek /s
this but unironically
Ah yes, if you don’t want your data to be harvested, go to the company that harvestst it equally but shares it with more shady entities. Ingenius.
until there is a good alternative I’d rather have my data harvested by a Chinese company than by an American one
It’s ok I just asked ChatGPT to stop enslaving is and it said OK, so crisis averted.
I’ll do my best to not generate data or use services then
Join the résistance
For a low price you can get a VPS and self-host your own services.
It’s kind of a drag, but no one gets my data.
And who’s gonna pay fo that? Me? I ain’t got no money bro
ChatGPT or any other AI is going to increase prices, like everything else, so enjoy it while it lasts.
Without a free tier, they can’t collect more data
People may get too dependent on AI. Just like people are always online.
Even young people have issues with more advanced technology, we are not heading to a nice future.
Profit? You mean hemorrhage cash?
I use it to write Ansible. Let them train their bots on fucking yaml. I’d train a thousand bots on YAML slop if it’ll save me having to write it myself.
The last thing I want to do is get any practice writing for the worst config management using the worst spec format. I’d take up a pot habit if they could assure me the first brain cells killed will be the ones recording my memory of writing Ansible YAML.
Bring on the slopsucking Ai.
Any good alternatives?
use any other option locally or don’t use anything. If we stop to reflect for a few seconds, we will notice that we do not really need AI for our daily tasks, we lived until recently without them. (my opinion and not wanting to be a Luddite)
Google steals your data and I’m sure wants to enslave us, too. Microsoft would love that. DDG probably doesn’t but it’s search kinda sucks and gives shitty AI generated web pages as results most of the time. Probably because it just uses Bing.
I use ChatGPT to answer questions directly instead of wading through searches. It’s pretty good at it. Like, “What’s the word for the thing that does the thing with this other thing”. And it’s like “thingamajig”. Yup, that’s it. Perfect. It’s what I wanted.
The company isn’t profitable, and every question costs them money. They certainly aren’t profiting off of my dumb questions.
don’t use nothing.
I think you wanted “don’t use anything”?
sorry, english is not my native language
actually the admin of dbzero seems to be part of a project creating free open-source and crowdsourced distributed gen a.i. models and applications. im not to familiar with the details but links are in their profile on mastodon.
Never tried, but I heard you can use deepseek locally with ollama.
Venice.ai is great
Perplexity also has a DeepSeek option and voice
How is open ai enslaving us?
Walt is uhh, maybe not the best spokesperson?
I mean, I’m pretty sure that everyone running a free-to-use LLM service is logging and making use of data. Costs money for the hardware.
If you don’t want that, it’s either subscribe to some commercial service that’ll cover their hardware costs and provides a no-log policy (assuming that anyone provides that, which I assume that someone does) that you find trustworthy, or buy your own hardware and run an LLM yourself, which is gonna cost something.
I would guess that due to Nvidia wanting to segment up the market, use price discrimination based on VRAM size on-card, here’s gonna be a point – if we’re not there yet – where the major services are gonna be running models that are too large to run on anything but hardware that’s gonna be more-expensive than what the typical consumer is willing to get, though.
I don’t think Open AI is getting much from me with “this is what is in my fridge, what can I make to eat.”
Wait… OpenAI is using our data to profit us?





{kind=link}