
Charlie Fish
Software Engineer (iOS) 🖥📱, student pilot ✈️, HUGE Colorado Avalanche fan 🥅, entrepreneur (rrainn, Inc.) ⭐️ https://charlie.fish/
- 74 Posts
- 90 Comments
Joined 3 years ago
Cake day: June 11th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.





 3·1 year ago
3·1 year agoIt really depends on what you’re trying to do. At the end of the day, the foundational components are pretty standard across the board. All machines have a CPU, motherboard, storage mechanism, etc. Oftentimes those actual servers have a form factor better suited for rack mounting. They often have more powerful components.
But at the end of the day, the difference isn’t as striking as most people not aware of this stuff think.
I’d say considering this is your first experience, you should start with converting an old PC due to the lower price point, and then expand as needed. You’ll learn a lot and get a lot of experience from starting there.
 811·1 year ago
811·1 year agoThis is not a “mistake”. This clearly proves they have Apple TV app integration implemented (just turned off). And someone accidentally turned it on.
But they have clearly put in effort and work into adding this functionality.
New functionality doesn’t just happen by mistake.
 2·1 year ago
2·1 year agoGot it. Thanks so much for your help!! Still a lot to learn here.
Coming from a world of building software where things are very binary (it works or it doesn’t), it’s also really tough to judge how good is “good enough”. There is a point of diminishing returns, and not sure at what point to say that it’s good enough vs continuing to learn and improve it.
Really appreciate your help here tho.
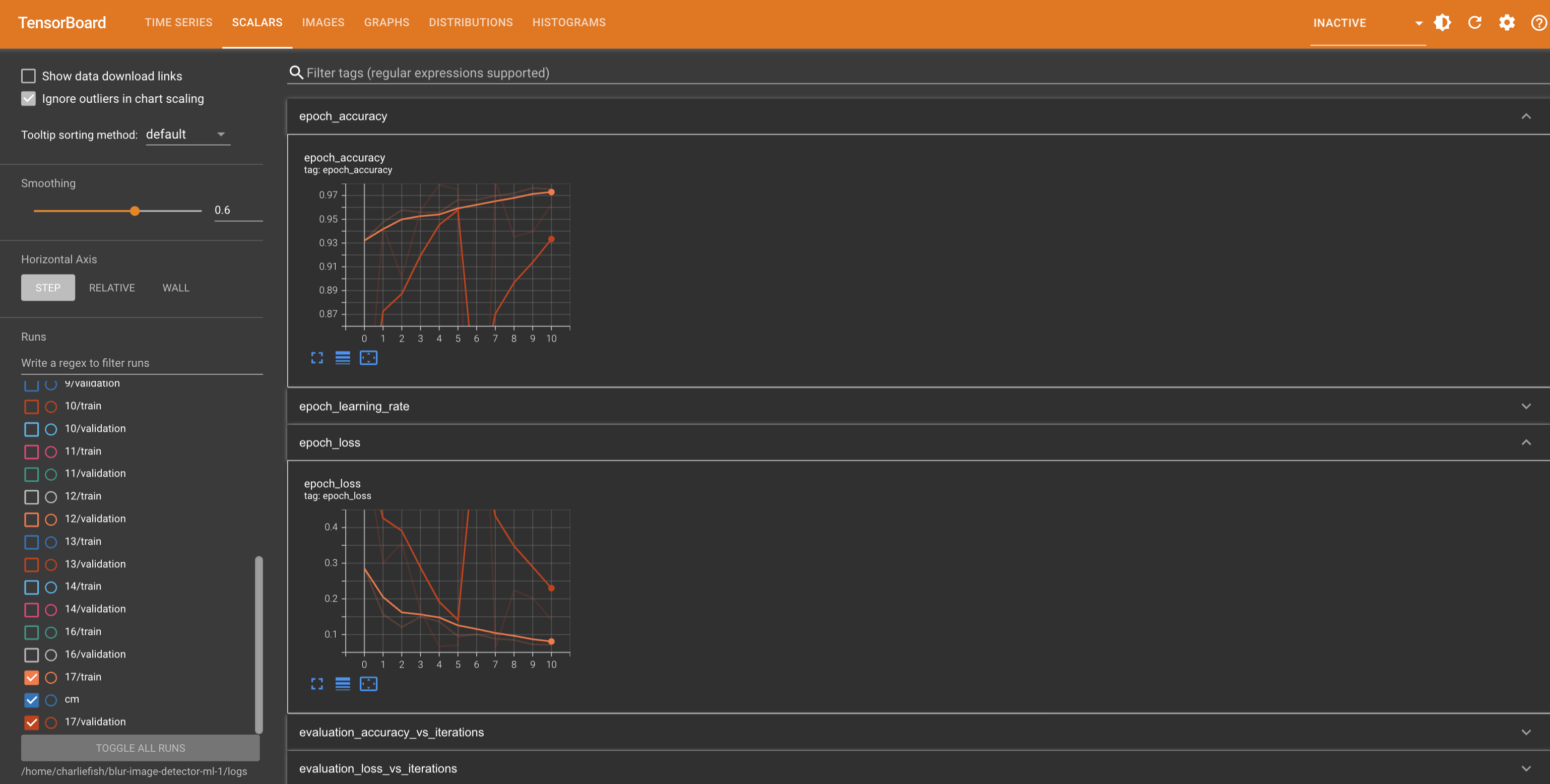
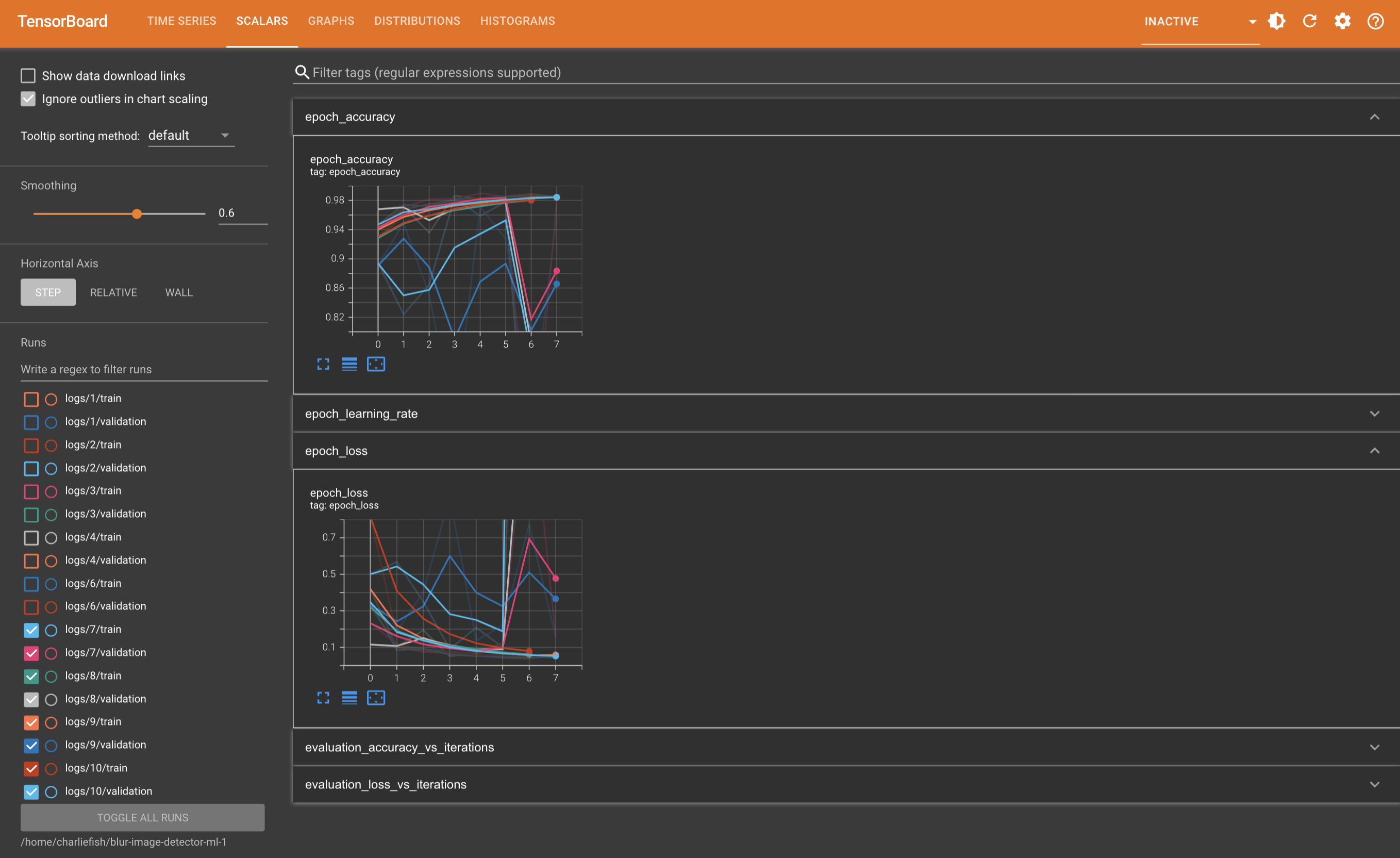
So someone else suggested to reduce the learning rate. I tried that and at least to me it looks a lot more stable between runs. All the code is my original code (none of the suggestions you made) but I reduced the learning rate to 0.00001 instead of 0.0001.
Not quite sure what that means exactly tho. Or if more adjustments are needed.
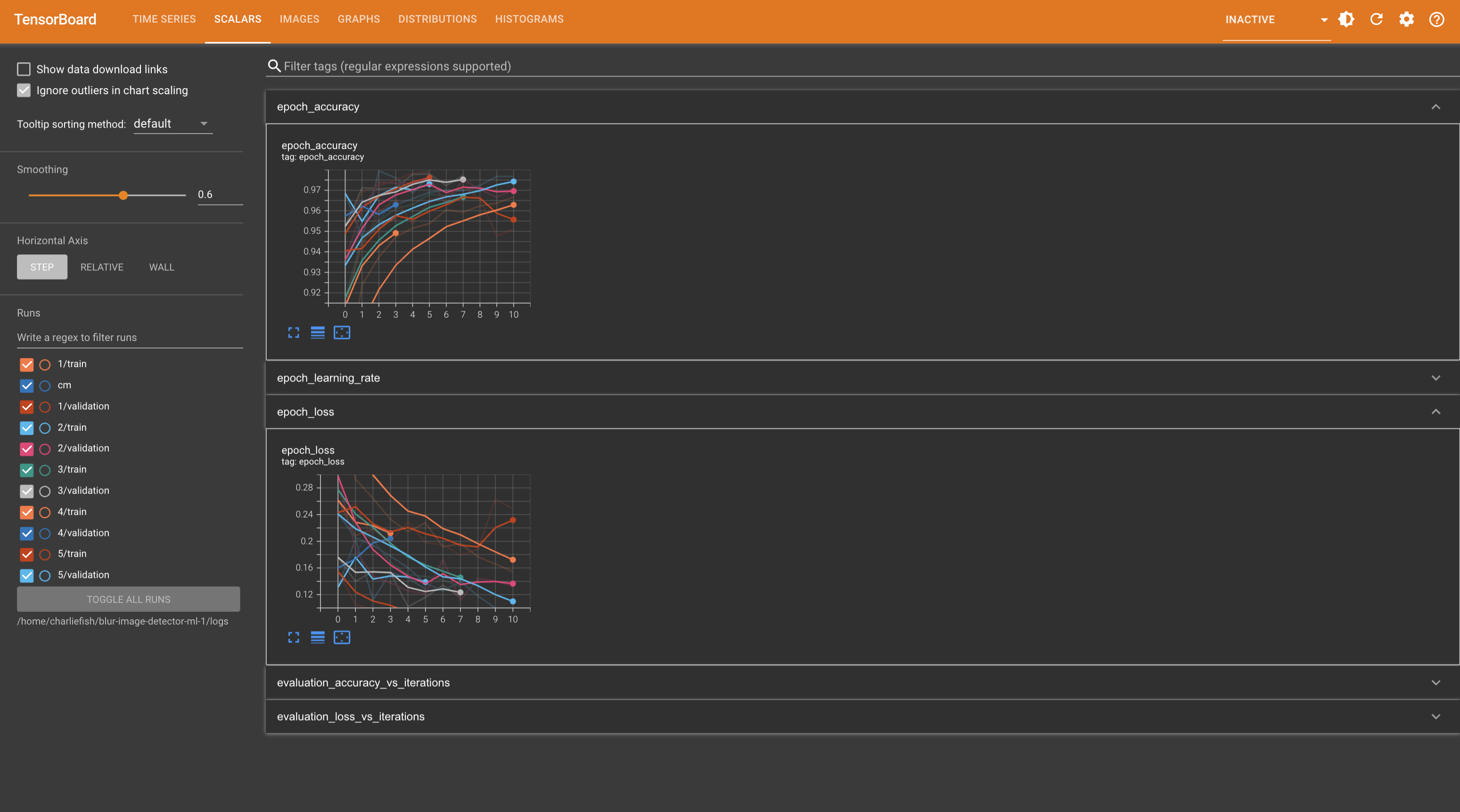
As for the confusion matrix. I think the issue is the difference between smoothed values in TensorBoard vs the actual values. But I just ran it again with the previous values to verify. It does look like it matches up if you look at the actual value instead of the smoothed value.
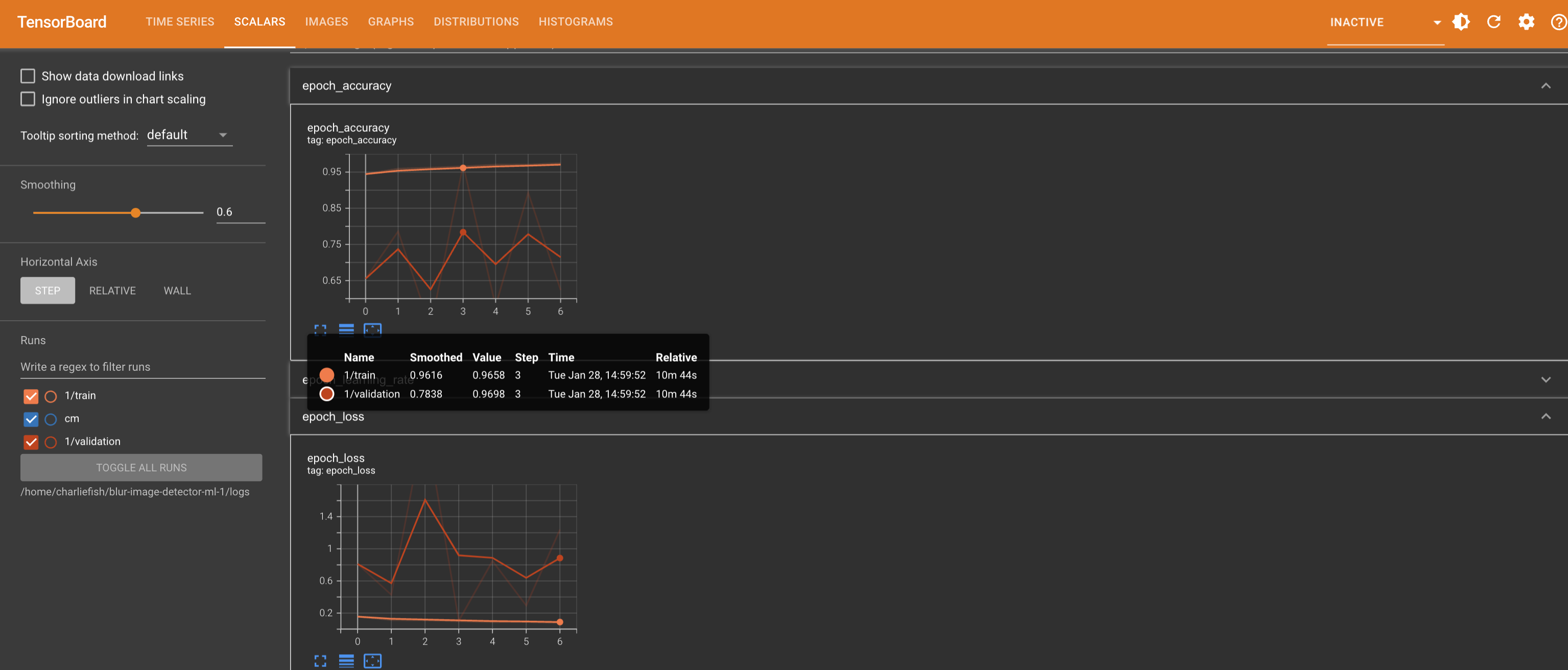
Sorry for the delayed reply. I really appreciate your help so far.
Here is the raw link to the confusion matrix: https://eventfrontier.com/pictrs/image/1a2bc13e-378b-4920-b7f6-e5b337cd8c6f.webm
I changed it to
keras.layers.Conv2D(16, 10, strides=(5, 5), activation='relu'). Dense units still at 64.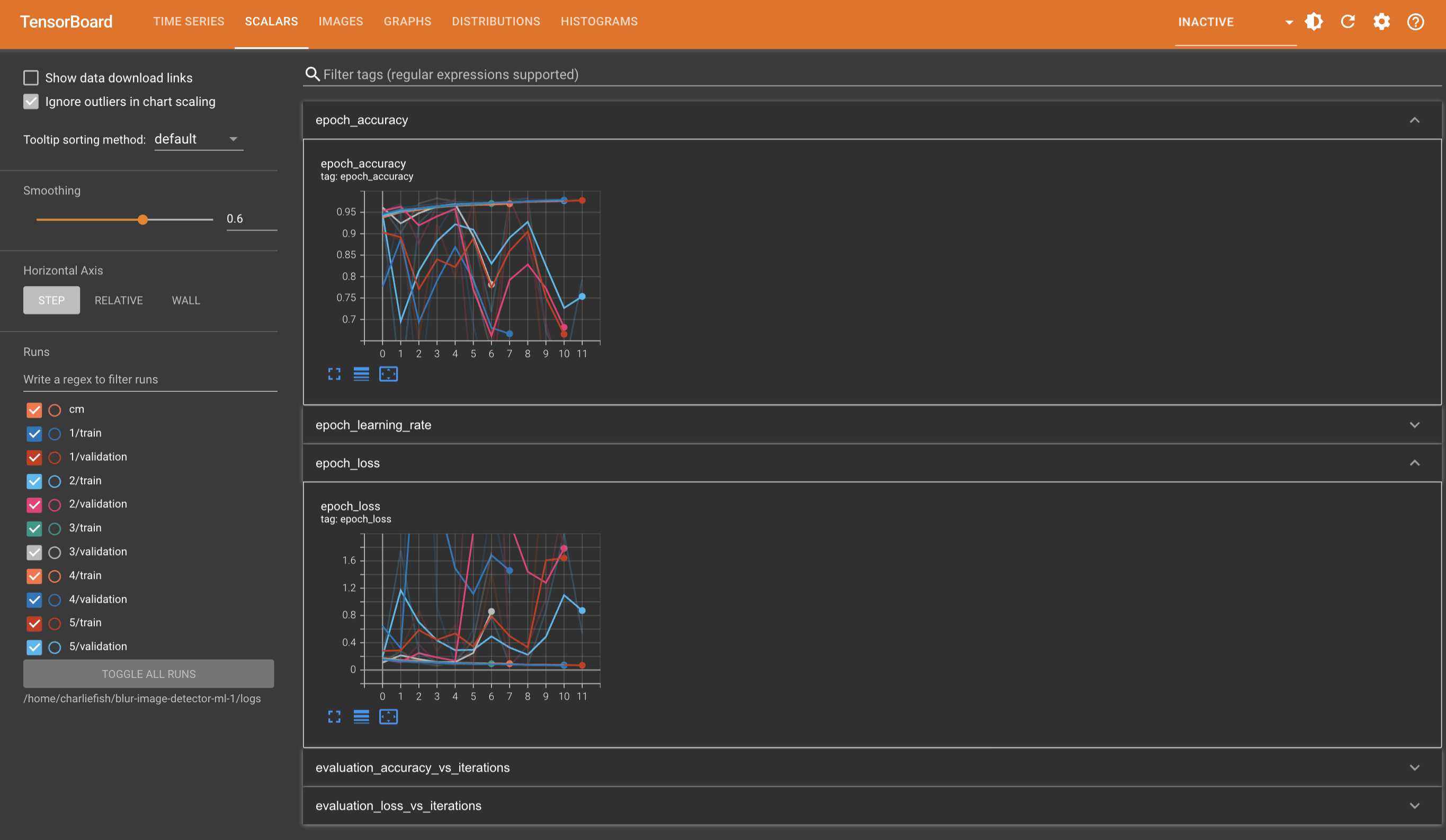
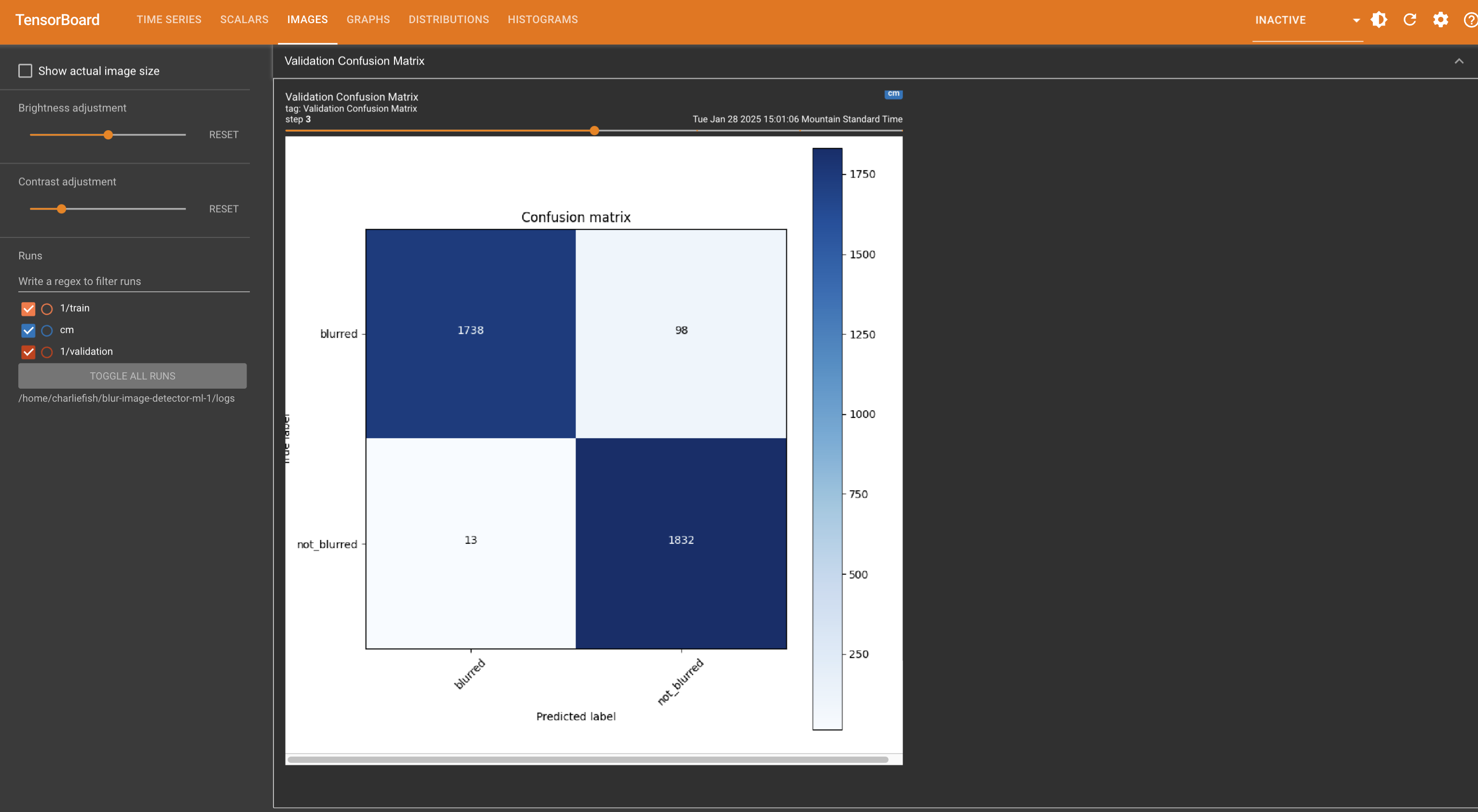
And in case the confusion matrix still doesn’t work, here is a still image from the last run.
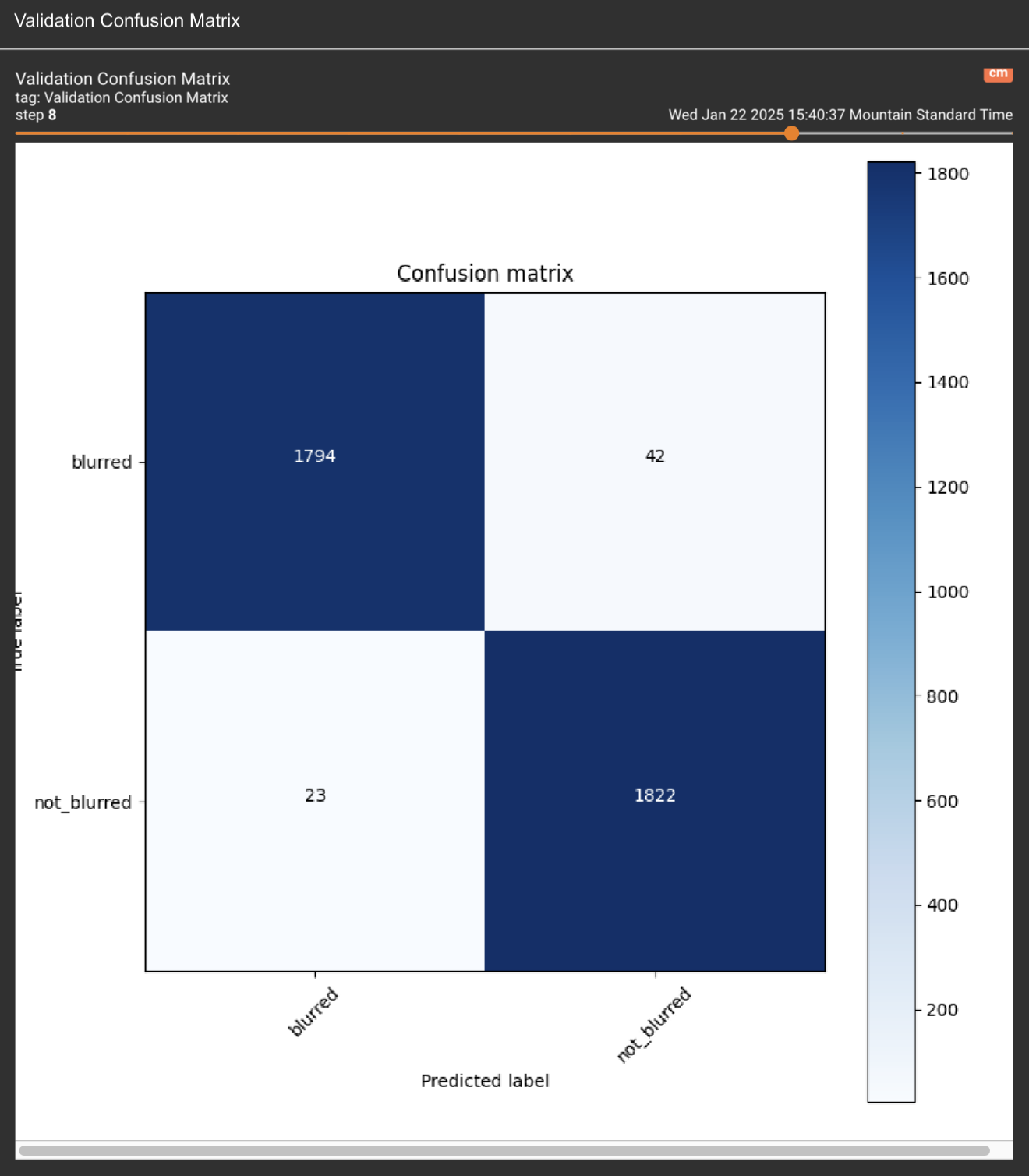
EDIT: The wrong image was uploaded originally.
Ok I changed the Conv2D layer to be 10x10. I also changed the dense units to 64. Here is just a single run of that with a Confusion Matrix.
I don’t really see a bias towards non-blurred images.
So does the fact that they aren’t converging near the same point indicate there is a problem with my architecture and model design?
Got it. I’ll try with some more values and see what that leads to.
So does that mean my learning rate might be too high and it’s overshooting the optimal solution sometimes based on those random weights?
I think what you’re referring to with iterating through algorithms and such is called hyper parameter tuning. I think there is a tool called Keras Tuner you can use for this.
However. I’m incredibly skeptical that will work in this situation because of how variable the results are between runs. I run it with the same input, same code, everything, and get wildly different results. So I think in order for that to be effective it needs to be fairly consistent between runs.
I could be totally off base here tho. (I haven’t worked with this stuff a ton yet).
Thanks so much for the reply!
The convolution size seems a little small
I changed this to 5 instead of 3, and hard to tell if that made much of an improvement. It still is pretty inconsistent between training runs.
If it doesn’t I’d look into reducing the number of filters or the dense layer. Reducing the available space can force an overfitting network to figure out more general solutions
I’ll try reducing the dense layer from 128 to 64 next.
Lastly, I bet someone else has either solved the same problem as an exercise or something similar and you could check out their network architecture to see if your solution is in the ballpark of something that works
This is a great idea. I did a quick Google search and nothing stood out to start. But I’ll dig deeper more.
It’s still super weird to me that with zero changes how variable it can be. I don’t change anything, and one run it is consistently improving for a few epochs, the next run it’s a lot less accurate to start and declines after the first epoch.


 4·1 year ago
4·1 year agoThat’s attached to the instance? Do you have a screenshot maybe?
What is the error that you get?




Yes. It just will fill your feed with a bunch of things you might not care about. But admin vs non admin doesn’t matter in the context of what I said.
Your instance is the one that federates. However it starts with a user subscribing to that content. Your instance won’t federate normally without user interaction.
Normally the solution for the second part is relays. But that isn’t something Lemmy supports currently. This issue is very common with smaller instances. It isn’t as big of a deal with bigger instances since users are more likely to have subscribed to more communities that will automatically be federated to your instance. You could experiment with creating a user and subscribing to a bunch of communities so they get federated to your instance.
It’s not really any different than hosting any other service.
 9·1 year ago
9·1 year agoI was lucky to get in in the early days when posting Mastodon handles on Twitter was common so was able to easily migrate. But this is a problem with ActivityPub right now I feel like. Discovery algorithms can be awful in the timeline, but so useful for finding people/communities to follow.
 1·1 year ago
1·1 year agoYep just saw that too after I researched it a bit more. What is strange is I don’t remember Eve Energy having a firmware update since then. Makes me wonder if they had it ready to go in previous firmware versions based on internal specs they saw? Or maybe I just forgot about a firmware update I did.


but as the Matter standard doesn’t yet support energy monitoring, users are limited to basic features like on and off and scheduling
- from this link
Granted the article is almost a year old. But I just didn’t realize that Matter now supports energy monitoring. Somehow I just missed that news.



I’m not aware of any official Ubiquiti certifications. Maybe it was a 3rd party certification? Someone else might know more than I do tho.
Most dash cameras that have an SD card slot just record over existing footage once it runs out of storage.
So get a large-capacity SD card. Have it record everything. Then every so often, take that SD card, put it into your laptop, and offload it wherever you want (NAS, cloud storage, etc.).